E.g. gemini-3-pro tops the lmarena text chart today at 1488 vs 1346 for gpt-4o-2024-05-13. That's a win rate of 70% (where 50% is equal chance of winning) over 1.5 years. Meanwhile, even the open weights stuff OpenAI gave away last summer scores between the two.
The exception seems to be net new benchmarks/benchmark versions. These start out low and then either quickly get saturated or hit a similar wall after a while.
Why do you care about LM Arena? It has so many problems, and the fact that no one would suggest using GPT-4o for doing math or coding right now, or much of anything, should tell you that a 'win rate of 70%' does not mean whatever it looks like it means. (Does GPT-4o solve roughly as many Erdos questions as gemini-3-pro...? Can you write roughly as good poetry?)
The particular benchmark in the example is fungible but you have to pick something to make a representative example. No matter which you pick someone always has a reason "oh, it's not THAT benchmark you should look at". The benchmarks from the charts in the post exhibit the same as described above.
If someone was making new LLMs which were consistently solving Erdos problems at rapidly increasing rates then they'd be showing how it does that rather than showing how it scores the same or slightly better on benchmarks. Instead the progress is more like years since we were surprised LLMs were writing poetry to massage out an answer to one once. Maybe by the end of the year a few. The progress has definitely become very linear and relatively flat compared to roughly the initial 4o release. I'm just hoping that's a temporary thing rather than a sign it'll get even flatter.
One year ago coding agents could barely do decent auto-complete.
Now they can write whole applications.
That's much more difficult to show than an ELO score based on how people like emjois and bold text in their chat responses.
Don't forget Llama4 led Lmarena and turned out to be very weak.
LMArena is, de facto, a sycophancy and Markdown usage detector.
Two others you can trust, off the top of my head, are LiveBench.ai and Artifical Analysis. Or even Humanity’s Last Exam results. (Though, frankly, I’m a bit suspicious of them. Can’t put my finger on why. Just was a rather rapid hill climb for a private benchmark over the last year.)
FWIW GPT 5.2 unofficial marketing includes the Erdos thing you say isn’t happening.
> FWIW GPT 5.2 unofficial marketing includes the Erdos thing you say isn’t happening.
Certainly not, unless you're about to tell me I can pop into ChatGPT and pop out Erdos proofs regularly since #728 was massaged out with multiple prompts and external tooling a few weeks ago - which is what I was writing about. It was great, it was exciting, but it's exactly the slow growth I'm talking about.
I like using LLMs, I use them regularly, and I'm hoping they continue to get better for a long time... but this is in no way the GPT 3 -> 3.5 -> 4 era of mind boggling growth of frontier models anymore. At best, people are finding out how to attach various tooling to the models to eek more out as the models themselves very slowly improve.
Appstore releases were roughly linear until July 25 and are up 60% since then:
Generally, I've learned to warn myself off of a take when I start writing emotionally charged stuff like [1]. Without any prompting (who mentioned apps? and why would you without checking?), also, when reading minds, and assigning weak arguments, now and in my imagination of the future. [2]
At the very least, [2] is a signal to let the keyboard have a rest, and ideally my mind.
Bailey: > "If [there were] new LLMs...consistently solving Erdos problems at rapidly increasing rates then they'd be showing...that"
Motte: > "I can['t] pop into ChatGPT and pop out Erdos proofs regularly"
No less than Terence Tao, a month ago, pointing out your bailey was newly happening with the latest generation: https://mathstodon.xyz/@tao/115788262274999408. Not sure how you only saw one Erdos problem.
[1] "I'll wait with bated breath for the millions of amazing apps which couldn't be coded before to start showing up"
[2] "...or, more likely, be told in 6 months how these 2 benchmarks weren't the ones that should matter either"
How is this an exception? If a genius and kindergarden student takes a test to add two single digit numbers how is that result any relevant? Even though adding single digit number is in the class of possible test.
We can only look at non saturated test.
With average price of $6/hour that is $12,288/hour for whole cluster.
Times 33 days times 24 hours it comes out to be $9.7MM , assuming no discounts.
That leaves $10.3MM/6 months for salaries, which is 103 employees at $200k/year or 51 employee at $400k/year.
I don't think that was a good move. No other models do this.
No, deepseek did not spend only 5.5 million for Deepseek V3. No Gemini was not "entirely trained on TPUs". They did hundreds of experiments on GPUs to get to the final training run done entirely on TPUs. GCP literally has millions of GPUs and you bet your ass that the gemini team has access to them and uses them daily. Deepseek total cost to make Deepseek V3 is also in the 100-400 million range when you count all of what's needed to get to the final training run.
Edit: (Can't post cus this site's "posting too fast" thing is really stupid/bad)
The only way I can get reliable information out of folks like you is to loudly proclaim something wrong on the internet. I'm just going to even more aggressively do that from now on to goad people like you to set the record straight.
Even if they only used TPUs, they sure as shit spent orders of magnitude more than they claim due to "count the failed runs too"
You are wrong. Gemini was definitely trained entirely on TPU. Of course your point of "you need to count failed experiments, too". Is correct. But you seem to have misconceptions around how deepmind operates and what infra it possess. Deepmind (or barely any of Google internal stuff) runs on Borg, an internal cloud system, which is completely separate (and different) from gcp. Deepmind does not have access to any meaningful gcp resources. And Borg barely has any GPUs. At the time I left deepmind, the amount of tpu compute available was probably 1000x to 10000x larger than the amount of gpu compute. You would never even think of seriously using GPUs for neural net training, it's too limited (in terms of available compute) and expensive (in terms of internal resource allocation units), and frankly less well supported by internal tooling than tpu. Even for small, short experiments, you would always use TPUs.
A big segment of the market just uses GPU/TPU to train LLMs, so they don't exactly need flexibility if some tool is well supported.
Also, why are they comparing with Llama 4 Maverick? Wasn’t it a flop?
Page 9 of the technical report has more details, but it looks like they found some data prep methods as well as some other optimizations that overall worked out really well. I don't think it was any one particular thing.
As far as Llama 4 goes, it was only referenced as a similarly sized model, they called it one of their model "peers"; I don't think they intended any sort of quality comparison. Llama 4 was notable for sparsity, despite its poor performance and reception, some of the things they achieved technically were solid, useful research.
That said, there are folks out there doing it. https://github.com/lyogavin/airllm is one example.
128GB vram gets you enough space for 256B sized models. But 400B is too big for the DGX Spark, unless you connect 2 of them together and use tensor parallel.
Anyways, isn't a new Mac Studio due in a few months? It should be significantly faster as well.
I just hope RAM prices don't ruin this...
https://frame.work/products/desktop-diy-amd-aimax300/configu...
Training cost (FLOPs) = 6 * active params * total tokens. By keeping the MoE experts param count low, it reduces total training costs.
I don't think this was a good move. They should have just trained way past chinchilla like the other major labs, and keep sparsity above 2%. Even Kimi K2 is above 2%. GLM is at 5%, which makes it very expensive (and high performing) for its small size.
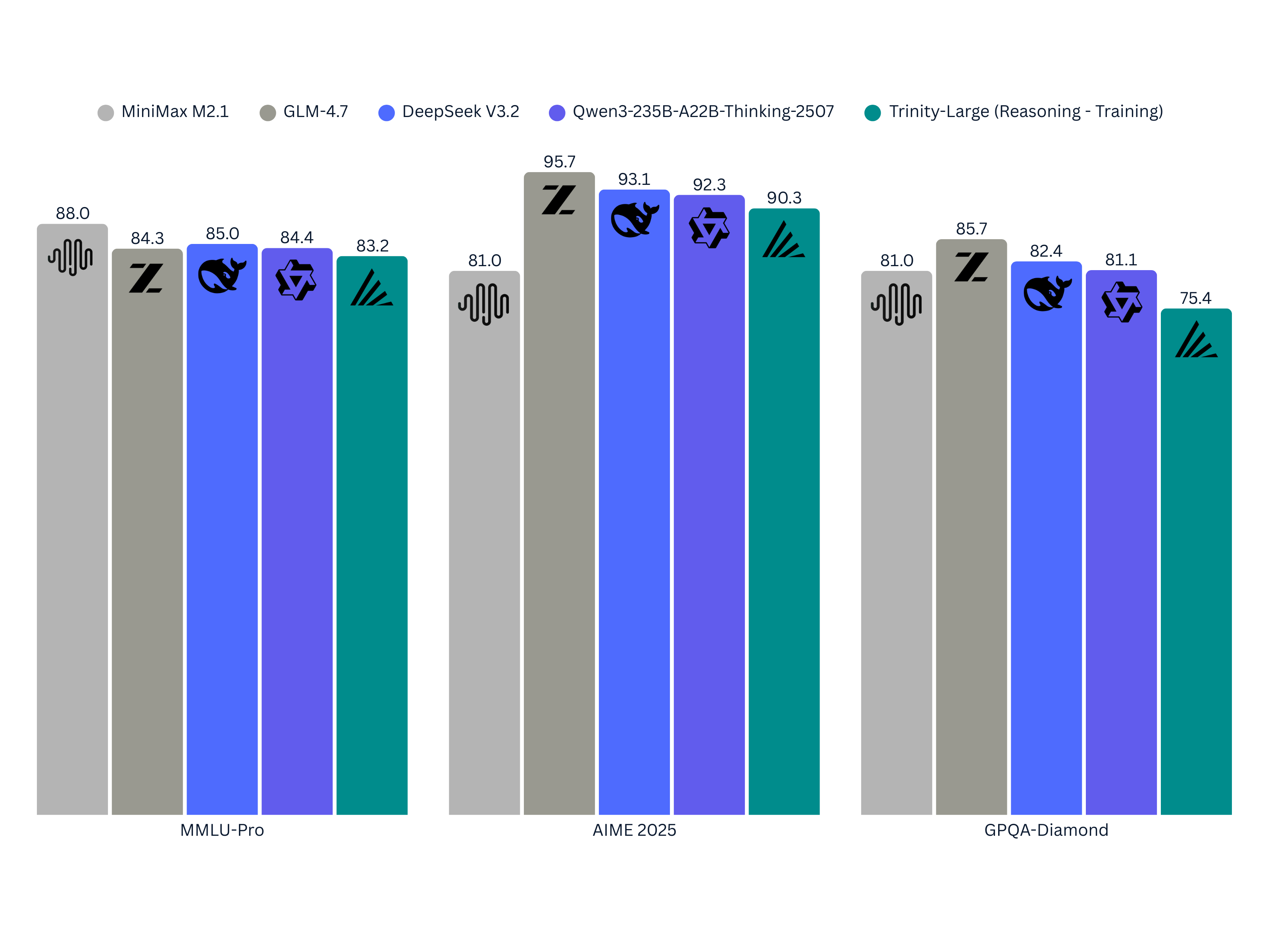
Arcee went the other way. They trained a massive 400b model (bigger than GLM-4.5/4.6/4.7, bigger than Qwen3 235b A23b), but only have 17b active params, which is smaller than Qwen and GLM. It's also only trained on 17T tokens, vs 20-30T+ tokens for the other models. It's just undertrained and undersized (in terms of active parameters), and they got much worse performance than those models:
https://45777467.fs1.hubspotusercontent-na1.net/hubfs/457774...
It's not a bad showing considering the limitations they were working with, but yeah they definitely need double the active experts (8 out of 256 instead of 4 out of 256) to be competitive. That would roughly double the compute cost for them, though.
Their market strategy right now is to have less active params so it's cheaper for inference, more total params so it's smarter for the amount of active params they have, but not too big to fit into a H200 cluster. I... guess this is a valid niche strategy? The target audience is basically "people who don't need all the intelligence of GLM/Qwen/Deepseek, but want to serve more customers on the H200 cluster they already have sitting around". It's a valid niche, but a pretty small one.
How do they plan to monetize?
{kind=link}